
Thursday, December 18th
Science 8

LiD ceremony - determination of LiD questions announced
Research LiD Question
Science 10
Quiz 8.1
finish lab 8-1F
soup can demo and analysis
read pgs. 362-363 & fill in foldable
Biology 12 - same as yesterday
LiD ceremony - determination of LiD questions announced
Research LiD Question
Science 10
Quiz 8.1
finish lab 8-1F
soup can demo and analysis
read pgs. 362-363 & fill in foldable
Biology 12 - same as yesterday
Wednesday, December 17th
Science 10 - QUIZ 8.1 & Same lesson as yesterday
Biology 12 - Research ethical question
Biology 12 - Research ethical question
Tuesday, December 16th
Science 8
1. Hand in LiD question
2. Hand in good copy of immune system map
3. Quiz 3.1
4. Read pgs. 110-114 & fill in chart
5. CYU questions #2,3,7,10 on page 117
Science 10
Review Activity 8-1F
https://www.youtube.com/watch?v=UoUzp6Wo638
https://www.youtube.com/watch?v=x2ve5yucNPQ
Complete Lab 8-1F
Review questions pg.361
Biology 12 - Same as Monday, December 15th
1. Hand in LiD question
2. Hand in good copy of immune system map
3. Quiz 3.1
4. Read pgs. 110-114 & fill in chart
5. CYU questions #2,3,7,10 on page 117
Science 10
Review Activity 8-1F
https://www.youtube.com/watch?v=UoUzp6Wo638
https://www.youtube.com/watch?v=x2ve5yucNPQ
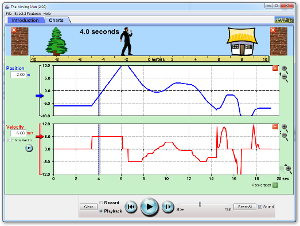
Complete Lab 8-1F
Review questions pg.361
Biology 12 - Same as Monday, December 15th
Monday, December 15th
Science 10 - Same as Friday, December 12th
Biology 12

1. Protein Synthesis & Mutations Quiz
2. Pick up practice workbook
3. Start Bioethics Project & choose ethical question
Biology 12
1. Protein Synthesis & Mutations Quiz
2. Pick up practice workbook
3. Start Bioethics Project & choose ethical question
Biology 12 - Bioethics Project Links
Referencing Instructions:
To prepare for the Bioethics Project choose at least two of the articles to read. You are welcome to search and find additional articles (possible sources: UBC, SFU, CBC, BBC, Discover, Scientific American).
Reference the articles you read and found useful for the Bioethics Project (include the article title and link).
Please provide the titles & links at the bottom of the page (or on an additional page) when you submit your answer to question #6. This submission should be typed.
Article links:
Genetic disorder - CSID
Genetic disorder - Cystic fibrosis
Genetic disorder - Cystic fibrosis
Genetic Disorder - Scizophrenia
Genetic Disorder - Autism
Genetic Disorder - Down Syndrome
Genetic Disorder - Down Syndrome
Genetic Disorder - Marfan's Syndrome
Genetic Disorder - Huntingtons Disease
Genetic Disorder - Heart disease
Friday, December 12th
Science 8
Review RC
Finish mapping activity & hand it in
Complete review questions on pg. 109
RESET portfolios for Term 2
Homework - select questions for LiD project
Science 10
Review RC on pg. 351
Read pgs. 353-354
Complete activity 8-1D
Start formal lab 8-1F
Biology 12
Same as December 11th
Review RC
Finish mapping activity & hand it in
Complete review questions on pg. 109
RESET portfolios for Term 2
Homework - select questions for LiD project
Science 10
Review RC on pg. 351
Read pgs. 353-354
Complete activity 8-1D
Start formal lab 8-1F
Biology 12
Same as December 11th
Thursday, December 11th
Science 10 - Same as December 10th
Biology 12
Hand in Vitamin C assignment
Finish GATTACA movie & journal page
Reminder - Protein synthesis/Mutation quiz next class
Learning Outcomes for quiz:
Biology 12
Hand in Vitamin C assignment
Finish GATTACA movie & journal page
Reminder - Protein synthesis/Mutation quiz next class
Learning Outcomes for quiz:
- Identify roles of DNA, mRNA, tRNA and ribosomes in transciption and translation
- Determine a sequence of amino acids from DNA using a mRNA codon table
- Use examples to explain how mutations in DNA change the sequence of amino acids and as a result may lead to genetic disorders
- Define and give examples of mutagens
DNA Replication Update:
Here is some more information on DNA Replication & a 'interesting' rap that clearly explains the whole process...
Rap Video: https://www.youtube.com/watch?v=1L8Xb6j7A4w
Rap Video: https://www.youtube.com/watch?v=1L8Xb6j7A4w
DNA Replication is Semi-Conservative
DNA replication of one helix of DNA results in two identical helices. If
the original DNA helix is called the "parental" DNA, the two
resulting helices can be called "daughter" helices. Each of these two
daughter helices is a nearly exact copy of the parental helix (it is not 100%
the same due to mutations). DNA creates "daughters" by using the
parental strands of DNA as a template or guide. Each newly synthesized strand
of DNA (daughter strand) is made by the addition of a nucleotide that is
complementary to the parent strand of DNA. In this way, DNA replication is
semi-conservative, meaning that one parent strand is always passed on to the
daughter helix of DNA.
The first step in DNA replication is the separation of the two DNA
strands that make up the helix that is to be copied. DNA Helicase untwists the
helix at locations called replication origins. The replication origin forms a Y
shape, and is called a replication fork. The replication fork moves down the
DNA strand, usually from an internal location to the strand's end. The result
is that every replication fork has a twin replication fork, moving in the
opposite direction from that same internal location to the strand's opposite
end.
When the two parent strands of DNA are separated to begin replication,
one strand is oriented in the 5' to 3' direction while the other strand is
oriented in the 3' to 5' direction. DNA replication, however, is inflexible:
the enzyme that carries out the replication, DNA polymerase, only functions in
the 5' to 3' direction. This characteristic of DNA polymerase means that the
daughter strands synthesize through different methods, one adding nucleotides
one by one in the direction of the replication fork, the other able to add
nucleotides only in chunks. The first strand, which replicates nucleotides one
by one is called the leading strand; the other strand, which replicates in
chunks, is called the lagging strand.
The Leading Strand
Since DNA replication moves along the parent strand in the 5' to 3'
direction, replication can occur very easily on the leading strand. As seen in
, the nucleotides are added in the 5' to 3' direction. Triggered by RNA
primase, which adds the first nucleotide to the nascent chain, the DNA
polymerase simply sits near the replication fork, moving as the fork does,
adding nucleotides one after the other, preserving the proper anti-parallel
orientation.
The Lagging Strand
The lagging strand replicates in small segments, called Okazaki
fragments. These fragments are stretches of 100 to 200 nucleotides in humans that
are synthesized in the 5' to 3' direction away from the replication fork. Yet
while each individual segment is replicated away from the replication fork,
each subsequent Okazaki fragment is replicated more closely to the receding
replication fork than the fragment before. The lagging strand must wait for a
patch of the parent helix to open up a short distance in front of the newly
synthesized strand before it can begin its synthesis back to the end of the
daughter strand. This "lag" time does not occur in the leading strand
because it synthesizes the new strand by following right behind as the helix
unwinds at the replication fork.
These fragments are then stitched
together by DNA ligase, creating a continuous strand.
Wednesday, December 10
Science 8
Review Activity 3-1
Watch Immune System Video
Read pgs. 102-105 & complete RC on pg.106
Start Immune System mapping activity
Science 10
Physics 8.1
Review RC pg. 347 & pgs. 344-347
Read pgs 348-351 --> add to foldable notes
Complete Activity 8-1B, 8-1C in notebooks
Homework - RC pg. 351 #1-3
Biology 12
Same as December 9th
Review Activity 3-1
Watch Immune System Video
Read pgs. 102-105 & complete RC on pg.106
Start Immune System mapping activity
Science 10
Physics 8.1
Review RC pg. 347 & pgs. 344-347
Read pgs 348-351 --> add to foldable notes
Complete Activity 8-1B, 8-1C in notebooks
Homework - RC pg. 351 #1-3
Biology 12
Same as December 9th
Tuesday, December 9th
Science 10
(Same as yesterday - Monday, December 8th)
Biology 12
The Vitamin C Activity is due today - please hand it in.
We are starting our Bioethics Project today by watching GATTACA.
Please use the handout to create the journal page below...
.jpg)
(Same as yesterday - Monday, December 8th)
Biology 12
The Vitamin C Activity is due today - please hand it in.
We are starting our Bioethics Project today by watching GATTACA.
Please use the handout to create the journal page below...
Monday, December 8
Congratulations Mr.Wenzel for completing his teaching practicum!
Mrs. Myles returns to Science 8 & 10 today
Science 8
How does the immune system protect the human body?
Complete human body project reflection
Read pgs.98 & 100
Create journal page - 4 ways to...
Complete activity 3-1
Science 10
Physics Chapter 8.1
Read pg.340-341
Complete activity on pg.341
Create foldable and paste into workbooks pg.343
Read pg. 344-347 & fill in part of the foldable
Homework - reading check pg.347
Biology 12

Mutation Videos
https://www.khanacademy.org/test-prep/mcat/biomolecules/genetic-mutations/v/an-introduction-to-genetic-mutations
Mutation Reading
.jpg)
.jpg)
.jpg)
Vitamin C Mutations Lab - Due next class
December 5
Biology 12
Mutation Videos
https://www.khanacademy.org/test-prep/mcat/biomolecules/genetic-mutations/v/an-introduction-to-genetic-mutations
Mutation Reading
Vitamin C Mutations Lab - Due next class
December 1-4
Biology 12
QUIZ - DEC 3/4
- describe the structure of DNA
- Describe the three steps of DNA semi conservative replication
- Identify the purpose and site of DNA replication
HOMEWORK
Homework: Please select a SHORT article or story about genetic engineering, gene therapy or a genetic disorder involving proteins (ex. Cystic Fibrosis). And e-mail it to my e-mail address by December 4th.
Check out Scientific American, Discover, BBC, CBC, etc...
Hannah.myles@sd41.bc.ca


Transcription
VIDEO - https://www.khanacademy.org/partner-content/crash-course1/crash-course-biology/v/crash-course-biology-111
Protein Synthesis Animations & quizzes
Gene Expression
Stages of Transcription
How Translation Works
Protein Synthesis
Vocabulary
Flashcards
QUIZ - DEC 3/4
- describe the structure of DNA
- Describe the three steps of DNA semi conservative replication
- Identify the purpose and site of DNA replication
HOMEWORK
Homework: Please select a SHORT article or story about genetic engineering, gene therapy or a genetic disorder involving proteins (ex. Cystic Fibrosis). And e-mail it to my e-mail address by December 4th.
Check out Scientific American, Discover, BBC, CBC, etc...
Hannah.myles@sd41.bc.ca
Protein Synthesis Research Notes
The
connection between genes and proteins.
It
was believed since the early 1900s that genes determine the way an organism
looks
through
enzymes that catalyze specific chemical reactions in the cell. In other words,
some
diseases
are caused by missing or defective enzymes. In the 1930s George Beadle and
Edward Tatum were able to definitively establish the link between genes and
enzymes in their exploration of the metabolism of a bread mold. They bombarded
the mold with X-rays and screened the survivors for mutants that differed in
their nutritional needs.
The
normal mold could grow on agar containing very little nutrients. Beadle and Tatum
identified mutants that could not survive on this minimal medium, because they
were unable to synthesize certain essential molecules from the minimal ingredients.
However, most of these nutritional mutants were able to survive on a complete
growth medium that includes all 20 amino acids and a few other nutrients.
They
suggested that the mutants were unable to survive because they lacked an enzyme
necessary to make the particular nutrient missing from the medium. By providing
the missing nutrient, the mutants were able to survive.
Their
results provided strong evidence for the one
gene–one polypeptide hypothesis.
Proteins
carry information in their amino acid sequence and nucleic acids carry
information
in
their nucleotide sequence.
To
get from DNA (in nucleic acid language) to protein (in amino acid language)
requires
two
steps:
During
transcription, a DNA strand provides a template for the synthesis of a
complementary
RNA strand. This RNA molecule is called mRNA.
The
use of mRNA provides protection for the genetic information contained in DNA.
Also,
more protein can be made simultaneously because many mRNA copies of a gene can
be made. Lastly, each mRNA can be translated many times.
During
translation, the instructions are converted from nucleic acid language to amino
acid language.
The genetic code:
There
are only 4 bases but 20 amino acids so it is not sufficient for one nucleotide
to
represent
one amino acid.
The
code must be a series of triplets (three bases) which indicate a particular amino
acid. The genetic instructions for a polypeptide chain are written in DNA as a
series of non overlapping three-nucleotide words called codons.
Sixty-one
of the 64 triplets code for amino acids.
The
codon AUG not only codes for the amino acid methionine, but also indicates the “start”
of translation.
Three
codons do not indicate amino acids but are “stop” signals marking the termination
of translation.
Some
amino acids are coded for by two or more codons but a given codon ALWAYS codes
for only one amino acid. i.e.
there is redundancy but no ambiguity. e.g., GAA and
GAG both mean glutamic acid, but never
mean any other amino acid.
The
process of transcription is much like DNA replication except that DNA is acting
as a template for the construction of mRNA rather than new DNA
Initiation
RNA polymerase separates
the DNA strands at a particular sequence called the promoter and bonds the RNA
nucleotides as they base-pair along the DNA template.
Like
DNA polymerase, RNA polymerase can only assemble a polynucleotide in its 5’ to
3’ direction.
Unlike
DNA polymerase, RNA polymerase is able to start a chain from scratch; it does
not need a primer.
Elongation
As
RNA polymerase moves along the DNA, it untwists the double helix, 10 to 20 bases
at time, adding bases by base pairing rules to form mRNA.
Remember
that in RNA, U rather than T is paired with A.
Behind
the point of RNA synthesis, the double helix re-forms and the mRNA molecule
peels away.
If
there is high demand for a protein, the cell can have several RNA polymerases transcribing
the same gene simultaneously to produce several mRNAs.
Termination
Transcription
proceeds until RNA polymerase transcribes a terminator sequence
(AATAAA).
The
mRNA is then released from the RNA polymerase and sent to the cytosol.
A
transcription unit is the sequence between the start and stop sequences –
generally speaking, one gene.
Translation
In
the process of translation, a cell interprets a series of codons along an mRNA
molecule
and
builds a polypeptide. That is, mRNA is translated from nucleic acid language to
amino
acid
language.
The
interpreter is transfer RNA (tRNA), which carries amino acids to a ribosome. The
ribosome
then adds each amino acid carried by tRNA to the growing end of the polypeptide
chain.
Each
tRNA carries a specific amino acid attached to the amino acid attachment site.
At
the other end of the tRNA is a group of three nucleotides called the anticodon that
binds by complementary base pairing to the nucleotides of a codon.
E.g., if
the codon on mRNA is UUU, a tRNA with an AAA anticodon and carrying phenylalanine
will bind to it.
The
tRNA molecule is a translator, because it can read a nucleic acid word (the mRNA
codon) and translate it to a protein word (the amino acid).
Initiation
Each
ribosome has a binding site for mRNA and three binding sites for tRNA molecules.
(1)
The P site holds the tRNA carrying the growing polypeptide chain.
(2)
The A site carries the tRNA with the next amino acid to be added to the chain.
(3)
A tRNA that has dropped off its amino acid leaves the ribosome at the E (exit) site.
A
ribosome binds to mRNA and begins looking for the start codon (AUG)
To
extract the message from the genetic code requires specifying the correct starting
point.
This
establishes the reading frame; subsequent codons are read in groups of three nucleotides.
When
it is found, it is displayed in the P site so tRNA molecules can attempt to recognize
it by complementary base pairing with their anticodon. When this occurs, the
two ribosomal subunits come together to form the functional ribosome.
The
tRNA with the anticodon complementary to AUG always carries methionine (met) so
it is always the first amino acid in every protein. The tRNA carrying methionine
enters the P site.
The
ribosome now displays the next codon in the A site and waits for the tRNA with
the complementary anticodon to recognize it.
If
the cellular demand for a protein is high, several ribosomes can translate the
same
mRNA
simultaneously
Elongation (~ 60
ms per peptide bond)
The
tRNA with an anticodon complementary to the next codon enters the A site
The
growing polypeptide chain on the tRNA at the P site, now one amino acid longer,
is transferred to the tRNA at the A site. The ribosome forms a new peptide bond
by transferring the amino acid from tRNA in the P site to the amino acid on the
tRNA in the A site
The
ribosome moves over one codon on the mRNA so that the next codon is now displayed
in the A site.
The
tRNA (now empty) that had been in the P site is moved to the E site and then leaves
the ribosome.
the
appropriate tRNA moves in and the ribosome attaches the amino acids (now 2 of
them) from the tRNA in the P site to the amino acid on the tRNA in the A site. The
chain is now three amino acids in length
These
steps of elongation continue to add amino acids codon by codon until the polypeptide
chain is completed.
Termination
The
elongation process continues until one of the three stop codons is reached displayed
in the A site.
There
is no tRNA which recognizes any of the stop codons but a release factor binds
to the stop codon and hydrolyzes the bond between the polypeptide and its tRNA
in the P site.
This
frees the polypeptide, so it is released from the ribosome.
A
ribosome requires less than a minute to translate an average-sized mRNA into a polypeptide.
During
and after synthesis, a polypeptide coils and folds to its three-dimensional
shape spontaneously.
VIDEO - https://www.khanacademy.org/partner-content/crash-course1/crash-course-biology/v/crash-course-biology-111
Protein Synthesis Animations & quizzes
Gene Expression
Stages of Transcription
How Translation Works
Protein Synthesis
Vocabulary
Flashcards
November 25/26
Science 8/10
Please contact Mr.Wenzel for more information.
Biology 12

Homework: Finish question sheet
Homework: Please select a SHORT article or story about genetic engineering, gene therapy or a genetic disorder involving proteins (ex. Cystic Fibrosis). And e-mail it to my e-mail address by December 4th.
Check out Scientific American, Discover, BBC, CBC, etc...
Hannah.myles@sd41.bc.ca




https://www.khanacademy.org/partner-content/crash-course1/crash-course-biology/v/crash-course-biology-110
Please contact Mr.Wenzel for more information.
Biology 12
Homework: Finish question sheet
Homework: Please select a SHORT article or story about genetic engineering, gene therapy or a genetic disorder involving proteins (ex. Cystic Fibrosis). And e-mail it to my e-mail address by December 4th.
Check out Scientific American, Discover, BBC, CBC, etc...
Hannah.myles@sd41.bc.ca
Page 1 of DNA SECTION in Journals
Students should be able to answer the following questions...
1. Describe the structure and function of DNA
2. Describe the three steps in the semi-conservative replication of DNA
- unzipping (DNA helicase)
- complimentary base pairing (DNA polymerase)
- joining of adjacent nucleotides (DNA polymerase)
3. Describe the purpose of DNA replication
4. Identify the site of DNA replication
Research Notes:
James Watson and Francis Crick worked out the 3D structure of DNA using molecular models made of wire
- The molecule consists of 2 chains wound together in a spiral (i.e., a double helix).
- The sides of the chains are made of alternating sugars and phosphates, like the sides of a rope ladder.
- The ladder forms a twist every ten bases.
- Pairs of nitrogenous bases, one from each strand, form the rungs of the ladder. In order for the ladder to have a uniform width, a small base must be paired with a large base. A pairs with T and C pairs with G. This is called complementary base pairing.
- The two strands are held together by hydrogen bonding between bases.
- Note that the chains have direction. Each strand has a 3’ end with a free OH group attached to deoxyribose and a 5’ end with a free phosphate (P) group attached to deoxyribose. This arrangement is called antiparallel.3. Replication of DNA
When a cell divides, the DNA must be doubled so that each daughter cell gets a complete copy. It is important for this process to be high fidelity because any errors made would be inherited by the offspring and these errors would tend to accumulate with each generation.
Because each strand is complementary to the other, each can form a template when separated. When a cell copies a DNA molecule, each strand serves as a template for ordering nucleotides into a new complementary strand. One at a time, nucleotides line up along the template strand according to the base-pairing rules.
An experiment in the late 1950s by Matthew Meselson and Franklin Stahl demonstrated
that replication was semiconservative.
- The replication of a DNA molecule begins at special sites, origins of replication. A specific sequence of nucleotides marks the origin. (a sequence of about 150 nucleotides rich in GATC)
- Humans have hundreds of origins from which replication proceeds on both strands in both directions.
- At the origins, the DNA strands are separated, forming a replication “bubble” with replication forks at each end. An enzyme called helicase separates the strands.
- Elongating a new strand
- After the two strands are separated, DNA polymerase reads the bases on the template strand and attaches complementary bases to form a new strand. (DNA polymerase works at a rate of about 50 nucleotides per second)
- DNA polymerase can only attach the 5' phosphate (P) of one nucleotide to the 3' hydroxyl (OH) of the previous nucleotide that is already part of a strand. The enzyme can only work by building a new strand in the 5' ÿ 3' direction.
Problem of antiparallel strands
- Remember that the DNA molecule is arranged with the strands going in opposite directions so the 3' end of one strand is aligned with the 5' end of the other.
- DNA polymerase adds nucleotides only to the 3' end but can only do this on one strand, the leading strand.
- The other strand has a 5' P at the end rather than a 3' OH like DNA polymerase needs. This strand, the lagging strand, must be made in short fragments (Okazaki fragments) going in the direction opposite to the leading strand. Another enzyme, DNA ligase, then fills in the gaps by joining the fragments together. (fragments are 100-200 nucleotides in eukaryotes; 1000-2000 in prokaryotes)g. Priming DNA synthesis
AP BIOLOGY ONLY...
- DNA polymerases cannot initiate the synthesis of a new strand of DNA.
- A short stretch of RNA (5-10 nucleotides) with an available 3’ end is built. This short piece is called a primer and is built by primase, a RNA polymerase.
- After formation of the primer, DNA polymerase can add new nucleotides to the 3’end of the RNA primer.
- The leading strand requires the formation of only a single primer as the replication fork continues to separate. For synthesis of the lagging strand, each Okazaki fragment must have its own primer.
- Another DNA polymerase then replaces the RNA nucleotides of the primers with DNA nucleotides.
Replication error rate, DNA damage and repair
The active site of DNA polymerase must recognize all four nucleotides. This means that it is difficult to determine if a nucleotide is mistakenly in the active site.
Mistakes during the initial pairing of template nucleotides and complementary nucleotides occur at a rate of one error per 100,000 base pairs.
DNA polymerase checks for these errors by checking the width of the helix. The final error rate is only one per ten billion nucleotides.
Constant exposure to chemicals, viruses, and radiation also cause damage to DNA so human cells have about 130 enzymes which constantly check DNA for errors.
***
Video
https://www.khanacademy.org/partner-content/crash-course1/crash-course-biology/v/crash-course-biology-110
Concept Learning Outcomes from Term 1
B1 Cell
Structure
It
is expected that students will:
Describe the following cell structures
and their functions:
- cell membrane
- mitochondria
- smooth and rough
endoplasmic reticulum
- ribosomes
- Golgi bodies
- vesicles
- vacuoles
- lysosomes
- nuclear envelope
- nucleus
- nucleolus
- chromosomes
identify the functional interrelationships of cell structures
identify the cell structures in diagrams and electron micrographs
B2 - Water
It
is expected that students will:
- describe how the polarity of the water molecule results in hydrogen bonding
- describe the role of water as a solvent, temperature regulator, and lubricant
- Will be covered later this term: distinguish among acids, bases, and buffers, and indicate the importance of pH to biological systems
B4 - Biological
Molecules
It
is expected that students will:
- demonstrate a knowledge of synthesis and hydrolysis as applied to organic polymers
- distinguish among carbohydrates, lipids, proteins, and nucleic acids with respect to chemical structure
- recognize the empirical formula of a carbohydrate
- differentiate among monosaccharides, disaccharides, and polysaccharides
- differentiate among starch, cellulose, and glycogen
- list the main functions of carbohydrates
- compare and contrast saturated and unsaturated fats in terms of molecular structure
- describe the location and explain the importance of the following in the human body: neutral fats, steroids, phospholipids
- draw a generalized amino acid and identify the amine, acid (carboxyl), and R-groups
- differentiate among the primary, secondary, tertiary, and quaternary structure of proteins
- list the major functions of proteins
- relate the general structure of the ATP molecule to its role as the "energy currency" of cells
Know how these terms connect...
- Alpha
helix
·
Amino
acid*
·
ATP*
·
Beta
pleated sheet
·
Carbohydrate*
·
Cellulose*
·
Cholesterol
·
CnH2nOn
·
Double
Helix
·
DNA*
·
Disaccharide
·
Double
bonds between Carbons
·
Enzyme
·
Estrogen
·
Glucose
·
Glycerol
·
Glycogen
·
Hydrogen
bonding
·
Lipid*
·
Maltose
·
Monosaccharide
·
Neutral
fat (triglyceride)
·
Nucleotide
·
Nucleic
Acid
·
Peptide
bonds
·
Phospholipid*
·
Primary
·
Protein*
·
Polysaccharide
·
Quaternary
·
Ribose
·
RNA
·
Saturated
fatty acids
·
Secondary
·
Starch
·
Steroids
·
Sucrose
·
Tertiary
·
Testosterone
- Unsaturated Fatty Acid
- Unsaturated Fatty Acid
B9 - Transport
Across Cell Members
It
is expected that students will:
- apply knowledge of organic molecules - including phospholipids, proteins, glycoproteins, glycolipids, carbohydrates, and cholesterol to explain the structure and function of the fluid-mosaic membrane model
- identify they hydrophilic and hydrophobic regions
- explain why the cell membrane is described as "selectively permeable"
- compare and contrast the following: diffusion, facilitated transport, osmosis, active transport
- explain factors that affect the rate of diffusion across a cell membrane (eg. temperature, size of molecules, charge of molecule, concentration gradient)
- describe endocytosis, including phagocytosis and pinocytosis, and contrast it with exocytosis
- predict the effects of hypertonic, isotonic, and hypotonic environments on animal cell
B10 - SA:V Ratio
It is expected that students will:
It is expected that students will:
- demonstrate an understanding of the relationship and significance of surface area to volume, with reference to cell size
Subscribe to:
Posts (Atom)